





Hello hello,
I am back with yet another edition of “Simplify AI.” Today, I want to talk about one technology that has become extremely popular and is sitting underneath almost every useful AI feature today.
I am talking about Embeddings. Unfortunately, a lot of people still don’t still understand what embeddings are, how they work, and how AI PMs should think about them.
Here is my effort to simplify and answer all of the above questions.
What Are Embeddings
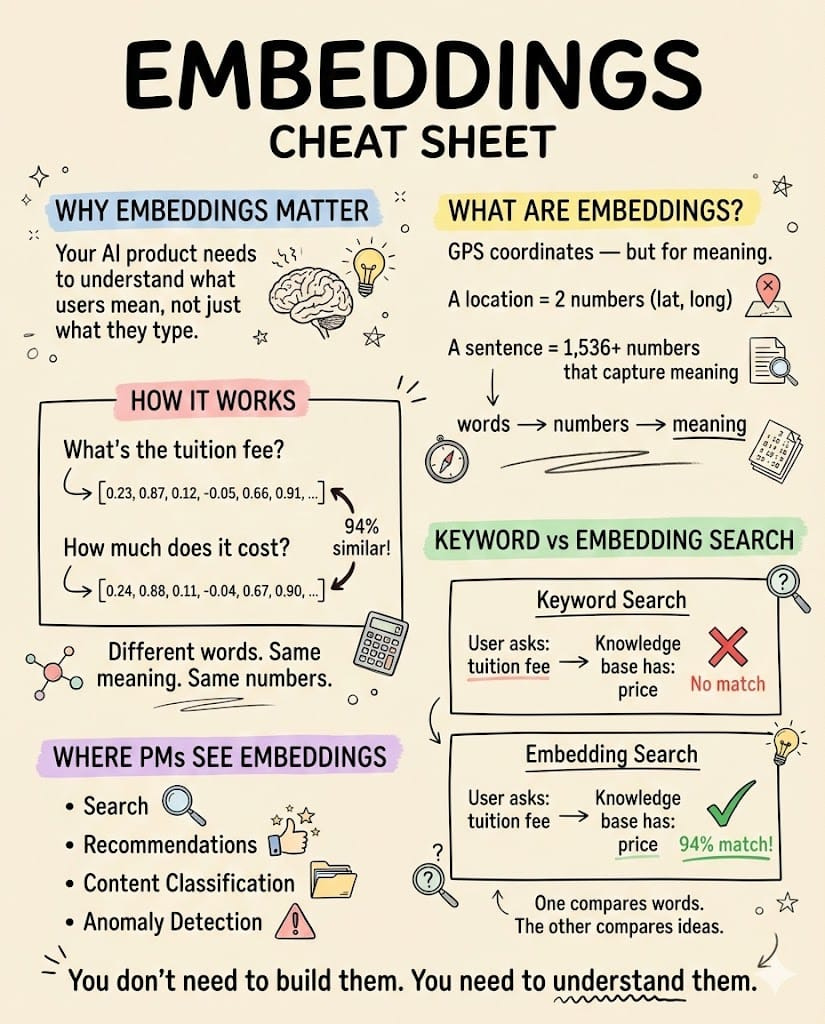
Think of embeddings as GPS coordinates for meaning.
A physical location can be represented by two numbers: latitude and longitude.
An embedding does the same thing for text, except instead of two numbers, it uses 1,536 (or more). Each sentence, paragraph, or document gets converted into a list of numbers that captures what it means, the actual concept behind the words. These two sentences produce nearly identical number patterns (embeddings):
- “What’s the tuition fee?”
- “How much does it cost?”
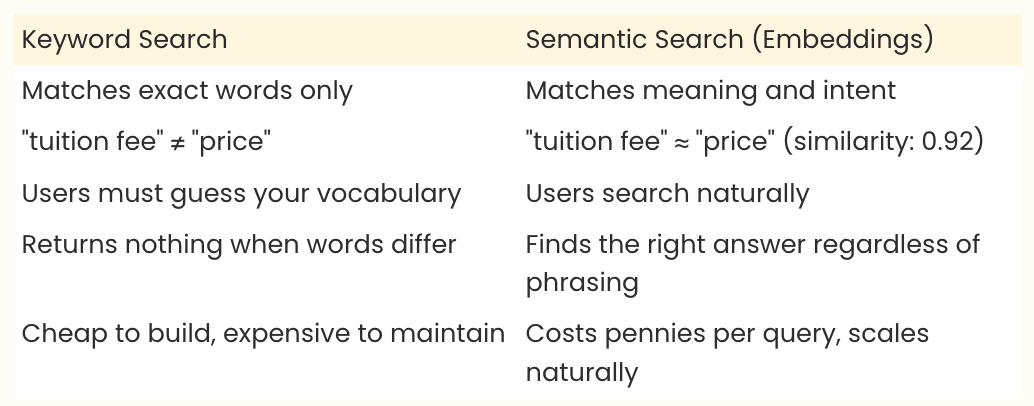
Different words. Same meaning. Same neighborhood in “meaning-space.” Meanwhile, “When does it start?” produces a completely different set of numbers because the intent is different, even though it shares common words like “does” and “it.” Traditional software compares strings of characters (or keywords).
Embeddings compare ideas and intent. That single difference changes how you build search, recommendations, and every AI-powered feature in your product.
💡 Pro Tip: When someone on your team says, “we’ll just use keyword search,” ask them what happens when a user types “cheap flights” but your database says “budget airfare.” If the answer is “nothing,” you need embeddings.
Why Embeddings Are the Foundation
Most AI concepts matter for one thing. Embeddings matter for almost everything.
Search, recommendations, chatbots that answer questions, spotting duplicate content, and sorting support tickets into categories. They all start the same way: converting something into an embedding (a list of numbers representing its meaning), then comparing it to other embeddings to find what’s most similar.
Spotify uses embeddings to recommend songs. Airbnb uses them to recommend listings.
Customer support bots use them to find the right help article. Different products, different industries, same core idea underneath. That’s what makes embeddings worth understanding more deeply than other AI concepts. They’re the shared foundation.
When your team builds an embedding system for search, that same system (and often the same embeddings) can power recommendations, grouping similar items together, and personalizing experiences later. One investment, multiple features.
The flip side matters too. If your embeddings are low quality, every feature built on top inherits the problem. Your search returns irrelevant results. Your chatbot gives wrong answers because it pulled the wrong reference material.
Your recommendations feel random.
Three different teams file three different bug reports, but the root cause is the same: the embeddings.
For PMs, that makes the embedding system one of the most important technical decisions on an AI product. You don’t need to pick the model yourself, but you need to understand the trade-offs well enough to ask the right questions when your engineering team proposes one. (More on those trade-offs later.)
How Semantic Search Outperforms Keyword Matching
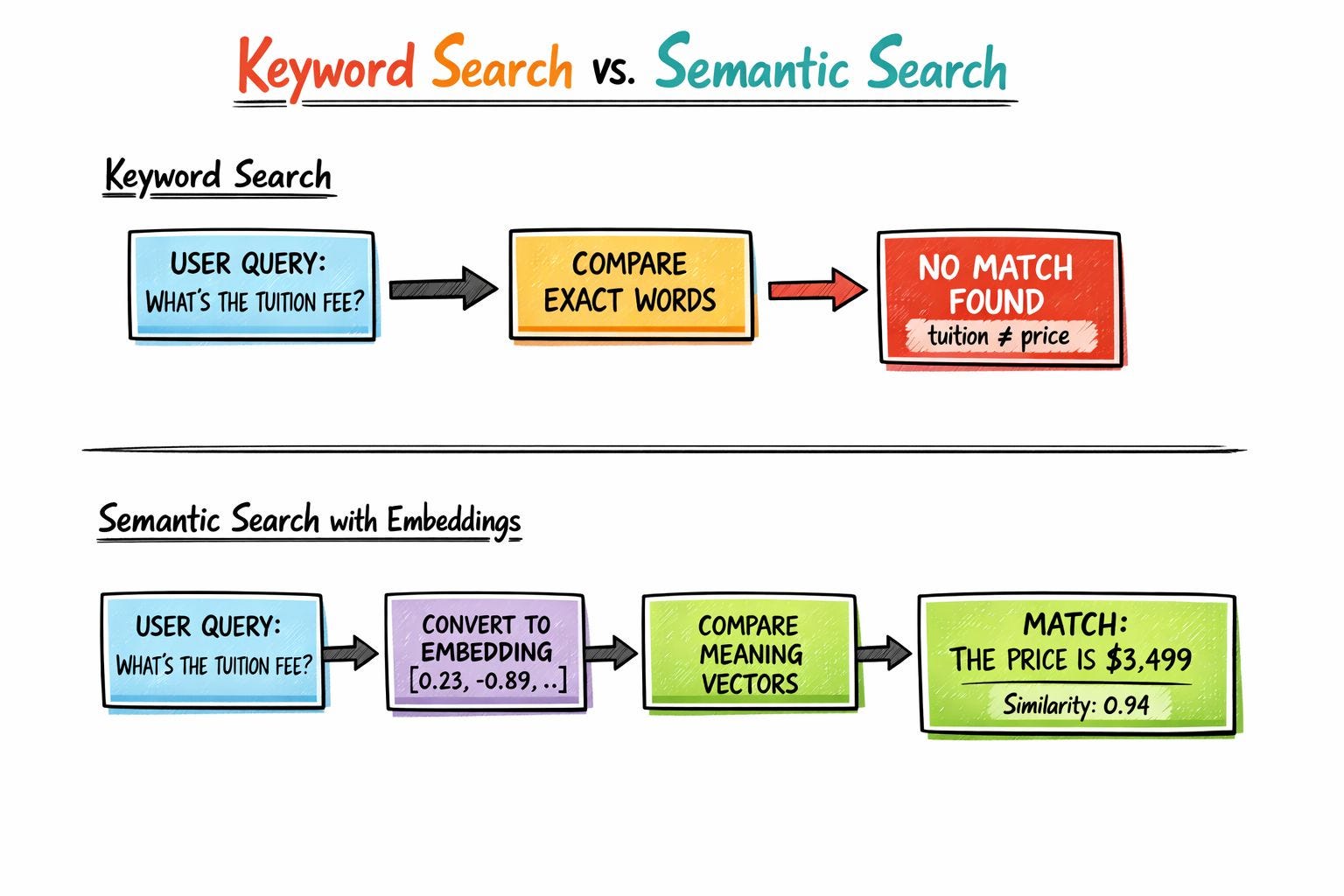
Keyword search works when your users guess the exact words your system expects. Semantic search (meaning-based search powered by embeddings) works when they don’t. A user emails a course platform asking, “What’s the tuition fee?”
The knowledge base contains: “The price is $3,499.” Keyword search returns nothing because “tuition” and “price” share zero characters. Embedding-based search returns the right answer immediately, with a similarity score of 0.94 out of 1.0 (where 1.0 means a perfect match in meaning).
Same question, same knowledge base, completely different result depending on how you built the search. Amazon Prime Video ran into this with sports content.
Someone searching for “soccer live” got documentaries like “This is Football: Season 1” and “Ronaldo vs Messi: Face Off!” instead of actual live matches.
The words overlapped enough for the keyword search to feel confident, but the intent was completely wrong. After deploying an embedding-based semantic search with a custom text-embedding model, Prime Video saw measurable improvements in search conversion and a drop in irrelevant results. Users started searching more often because the system finally understood what they meant.
Juicebox, an AI recruiting platform, saw similar gains across 800 million candidate profiles. A recruiter searching for “machine learning engineer” would miss profiles describing “ML practitioner” or “deep learning specialist.”
After switching to embedding-based search, the system found 35% more relevant candidates for complex queries. Same profiles in the database. The only change was how the search understood the question.
If your product uses keyword search for anything user-facing, embedding-based search will improve results. Your users are already frustrated by missed matches. They just aren’t telling you. They’re bouncing.
How Embeddings Power RAG (The System Behind Most AI Chatbots)
RAG stands for Retrieval Augmented Generation. The name is a mouthful, but the idea is simple: before an AI writes a response, it first looks up the relevant information, then uses what it found to write an answer.
This is the system behind most useful AI features today, from customer support chatbots to internal knowledge assistants. Embeddings are the engine that makes the “look up” step work. The system has three steps.
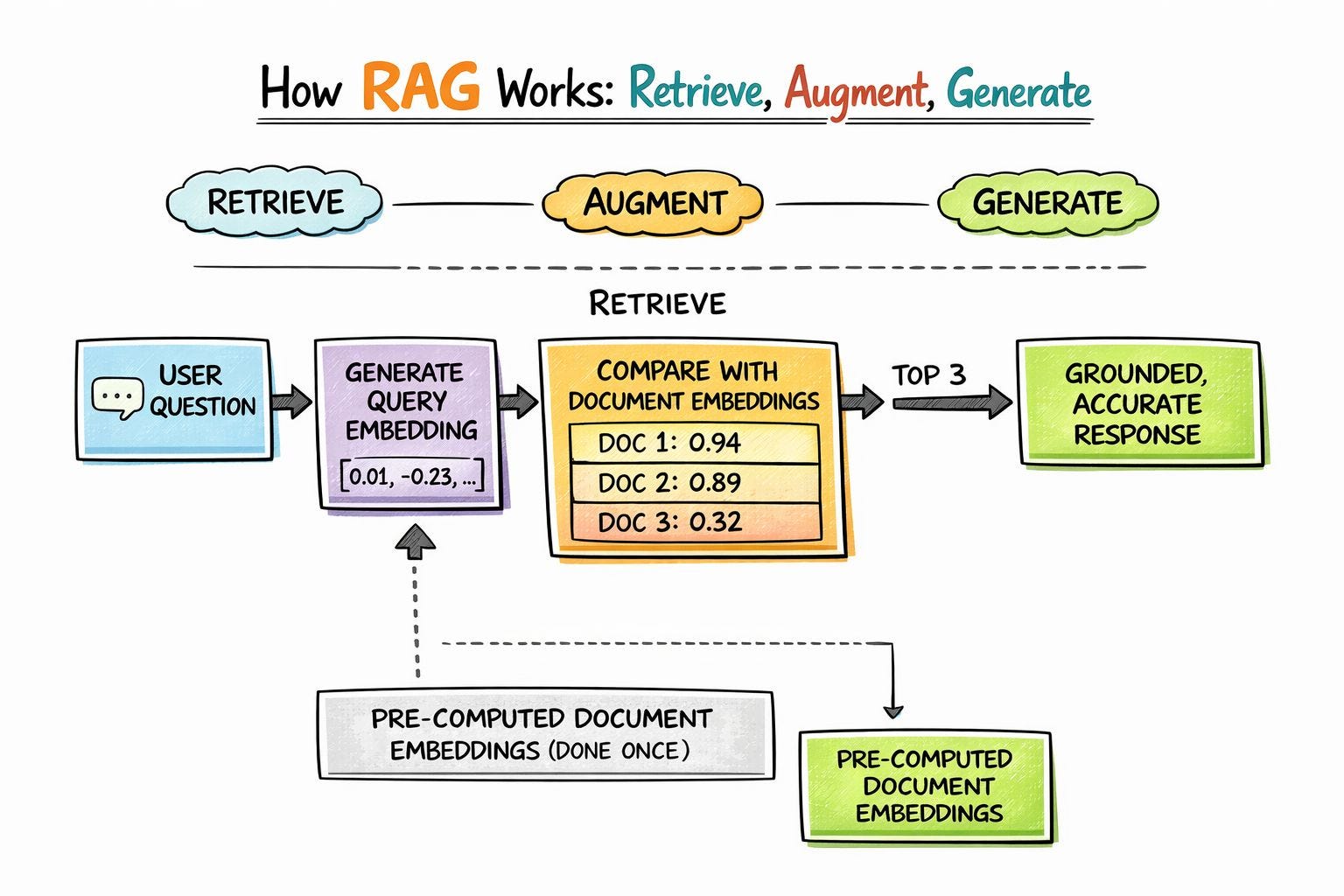
Step 1: Retrieve.
When a user asks a question, the system converts that question into an embedding (a list of numbers representing its meaning). Then it compares those numbers against a library of pre-converted document embeddings to find the closest matches. Think of it like asking, “which documents mean the most similar thing to this question?”
The most similar documents rise to the top.
Step 2: Augment.
The top-matching documents get attached to the question before it’s sent to the AI. Instead of hoping the AI already knows the answer from its training, you’re handing it the specific, verified information it needs right now.
Step 3: Generate.
The AI writes a response based on those retrieved documents.
The quality of your embeddings directly determines whether step one finds the right documents. Get that right, and the AI has what it needs to give a great answer.
Get it wrong, and you get a confident, well-written, completely incorrect response because the AI was given the wrong reference material to work with. Think of it like handing a brilliant new hire a filing cabinet.
If the files are organized by meaning (embeddings), they’ll pull the right document every time. If the files are organized alphabetically by filename (keywords), they’ll miss half the relevant information.
💡 Pro Tip: When your AI chatbot gives bad answers, check what documents it was given before blaming the AI itself. In most underperforming systems, the AI generates perfectly fine responses. It’s just working with the wrong information. Run ten real user queries, look at which documents the system retrieves, and see if the right information even makes it to the AI.
Liking this post? Get the next one in your inbox!
Real Companies, Real Results
Airbnb: Embedding Every Listing on the Platform
Airbnb’s engineering team published a paper at KDD 2018 (a top data science conference) describing how they built embeddings for their listings.
They trained on over 800 million search sessions across 4.5 million active listings. Each listing got its own set of numbers that captured its behavioral meaning: which travelers click on it, what they book afterward, and what they skip.
The Airbnb Engineering blog details the full implementation. Their “Similar Listings” carousel (the row of recommendations you see on a listing page) saw a significant increase in click-through rate during online testing, and more guests discovered the listing they ultimately booked through that carousel.
For a company processing millions of searches daily, that’s a meaningful revenue gain from a single change in how they organize information.
One clever detail: when a new listing was created with no interaction data, Airbnb generated a “cold start” embedding by averaging the numbers from the three closest existing listings with a similar type and price range. No user data needed. The system worked from day one.
Spotify: 16 Billion Discoveries Per Month
Spotify creates embeddings for everything: users, tracks, artists, playlists, and podcasts. Oskar Stål, VP of Personalization at Spotify, described these embeddings at Scale’s TransformX conference as “fingerprints for everything we have.”
Two teenage fans of Taylor Swift in the US will have similar user embeddings (similar lists of numbers). A 62-year-old jazz listener in the UK will have very different numbers. Same system, same math, completely different recommendations.
These embeddings power the recommendation engine behind 16 billion artist discoveries per month, meaning 16 billion times a month, a listener hears an artist they’ve never listened to before.
The system goes beyond matching songs by genre labels. It understands behavioral patterns, like the difference between what you listen to at 11 pm versus 7 am on a Monday, and uses those patterns to recommend the right music for the moment.
The Product Decisions Embeddings Force You to Make
Embeddings come with real trade-offs. Here are the ones you’ll face.
Which Embedding Model?
The market has exploded. OpenAI’s text-embedding-3-small is the most common starting point at $0.02 per million tokens (tokens are the chunks of text the model processes, roughly ¾ of a word each).
Open-source alternatives like E5-Mistral and BGE-M3 now rival commercial options in quality, with the added benefit of running on your own servers, where no data leaves your control. The core trade-off is speed-to-market versus data control.
Calling an API (sending your text to someone else’s server and getting back embeddings) gets you started in minutes. Running an open-source model on your own servers keeps everything private but adds setup work.
Your compliance team will have opinions here.
How Many Dimensions?
Remember the GPS analogy? A physical location needs 2 numbers. An embedding uses hundreds or thousands, and each number is called a “dimension.” More dimensions capture more nuance but cost more to store and search.
At 384 dimensions, you get fast, cheap results that miss subtle differences. At 1,536, you hit the sweet spot for most use cases. At 3,072, accuracy improves slightly, but storage and processing costs roughly double.
A customer support bot can probably work with fewer dimensions. A medical search tool, where pulling the wrong document could cause real harm, probably needs more.
Pre-Compute or Compute on the Fly?
Airbnb converts all its listing embeddings once a day in a scheduled batch job. Only the search query (what the user types) gets converted into an embedding in real-time. This is the standard approach, and for good reason.
Converting your entire knowledge base into embeddings once is cheap (pennies). Converting everything fresh on every single search query is expensive and slow.
Most content doesn’t change by the minute. A daily update works. Real-time conversion only makes sense if your data changes constantly, like a live stock trading dashboard or a breaking news feed.
What Similarity Threshold?
When the system compares two embeddings, it produces a score between 0 and 1.
A score of 0.9 means the meaning is nearly identical. A score of 0.3 means they’re unrelated. Most systems return the top 3 to 5 results regardless of score, but well-tuned systems add a minimum cutoff (typically 0.6 to 0.7) to filter out weak matches. This is a user experience decision disguised as a technical one.
Would you rather show users fewer, more accurate results, or more results with some irrelevant ones mixed in? There’s no universal right answer. It depends on what’s worse for your users: seeing nothing or seeing the wrong thing.
Key Takeaways
- Embeddings convert meaning into numbers, letting AI systems find matches that keyword search misses entirely.
- RAG (the system behind most AI chatbots) depends on retrieval quality. If your embeddings pull the wrong documents, even the best AI will generate wrong answers.
- Real companies get real results with embeddings. Airbnb improved its Similar Listings carousel, Spotify powers 16 billion monthly artist discoveries, and Juicebox surfaced 35% more relevant candidates.
- The model choice is a product decision. Data privacy, cost, and accuracy all trade off against each other.
- Pre-compute everything you can. Converting your knowledge base into embeddings once saves money and keeps your product fast.
That is it for today.
Until next time,
Sid
P.S. Don’t forget to let me know if you enjoyed this post.
More from
Product Management Concepts






