





Six months ago, running GPT-4-class responses at any real volume was super expensive. But now the numbers look different... and opposite.
The reason frontier models have become cheaper to run today is not that hardware has gotten better or that labs have become more efficient at training.
Much of it comes down to an architectural change that most PMs have never heard of: Mixture of Experts, or MoE. Understanding it might not make you an ML engineer.
However, it will make you a more credible person in the room when the team talks about model selection, latency, and cost.
Let’s dig in!
The Problem with Big Models
The AI industry had a problem. Bigger models are smarter. More parameters means more capability: better reasoning, more knowledge, stronger performance across tasks.
That’s been the case since the early days of large language models.
But bigger models are also expensive. Not just to train, but every time you call the model for an inference (every API request, chat turn, generated token), the model has to process your input through all of its parameters, every single one.
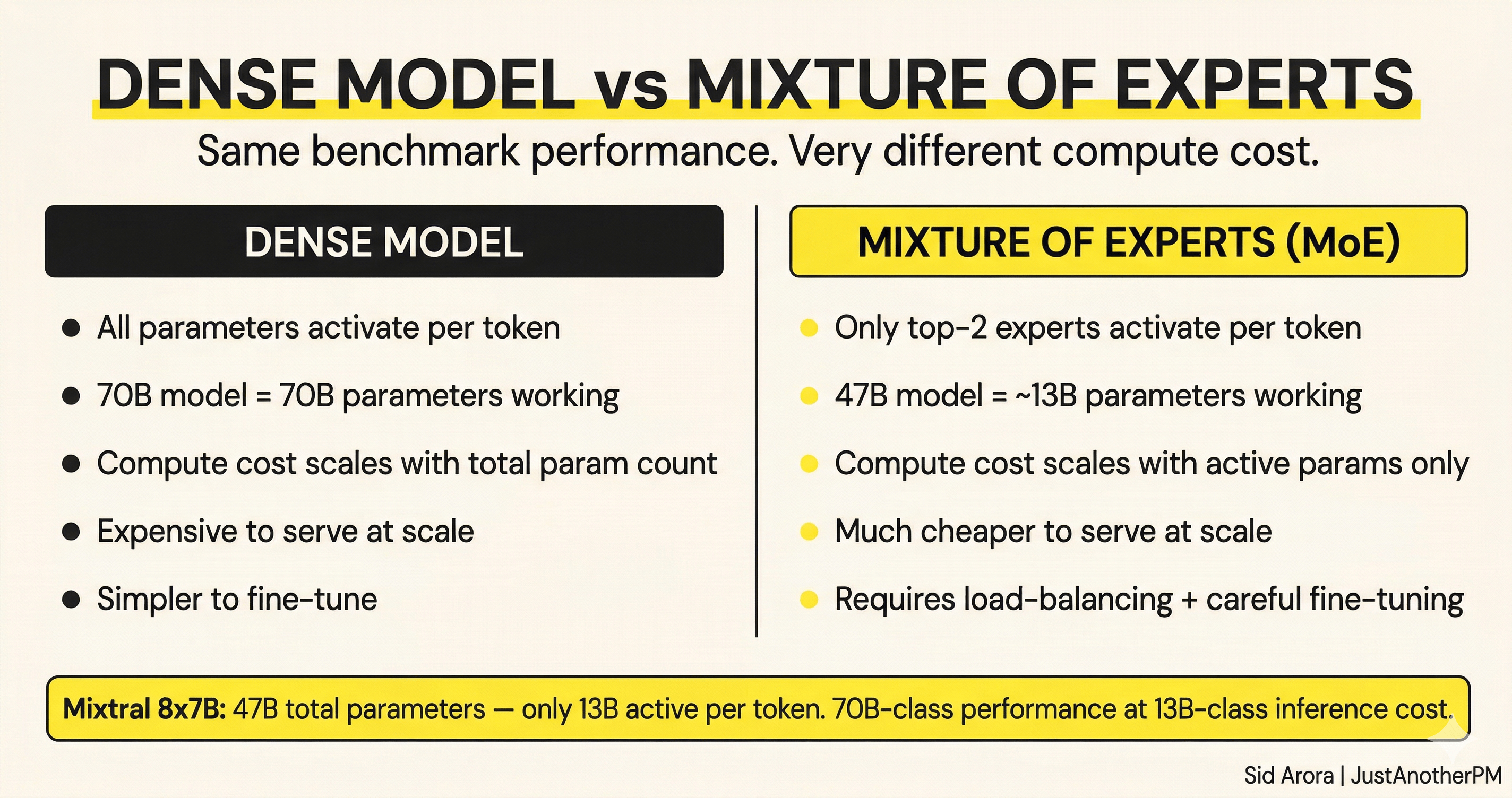
A 70-billion-parameter model uses all 70 billion parameters on every token it generates. That’s what researchers refer to as a dense model.
Also, all parameters remain active for all inputs all the time.
Imagine hiring a company of 1,000 specialists and requiring every single one of them to come and weigh in on every decision, even the unimportant ones.
That’s a dense model at inference time. And so much waste.
MoE is the answer to that waste.
What Mixture of Experts actually is
The core idea has been around since the early 1990s.
MIT researchers proposed it in a 1991 Neural Computation paper, but the modern version came into focus with Google’s Switch Transformer research in 2021.
It then became mainstream when Mistral released Mixtral 8x7B in December 2023.
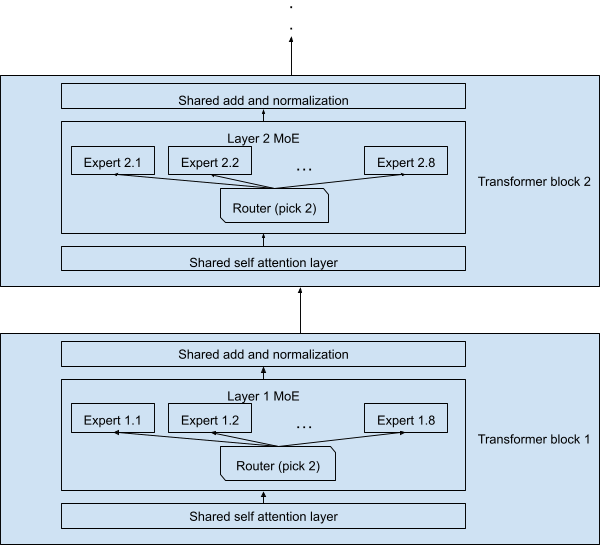
The concept is simple. Instead of one massive neural network that handles everything, an MoE model will have multiple smaller neural networks (the “experts”).
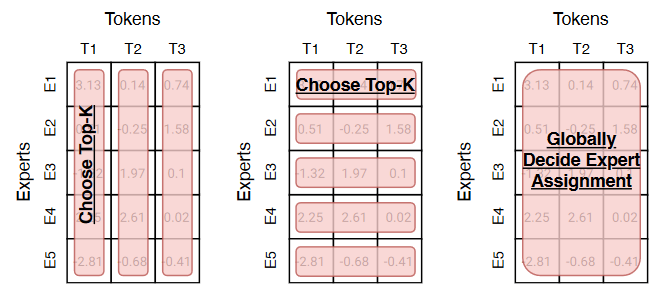
Then, a router decides which experts get called for each piece of input. Not all experts fire on every token. Only a small subset, usually two, activate at any given moment.
Think of it like a hospital. A general hospital has specialists in cardiology, neurology, orthopaedics, oncology, and dozens of other fields.
When a patient arrives, they don’t see all 400 doctors.
A triage system routes them to the right department. The orthopaedic surgeon handles the broken ankle. The cardiologist handles the chest pain.
The hospital’s total capacity is enormous.
But any given patient only activates a small fraction of it. That’s sparse activation. And it’s what makes MoE architecturally different from a dense model.
Liking this post? Get the next one in your inbox!
How the Router Works
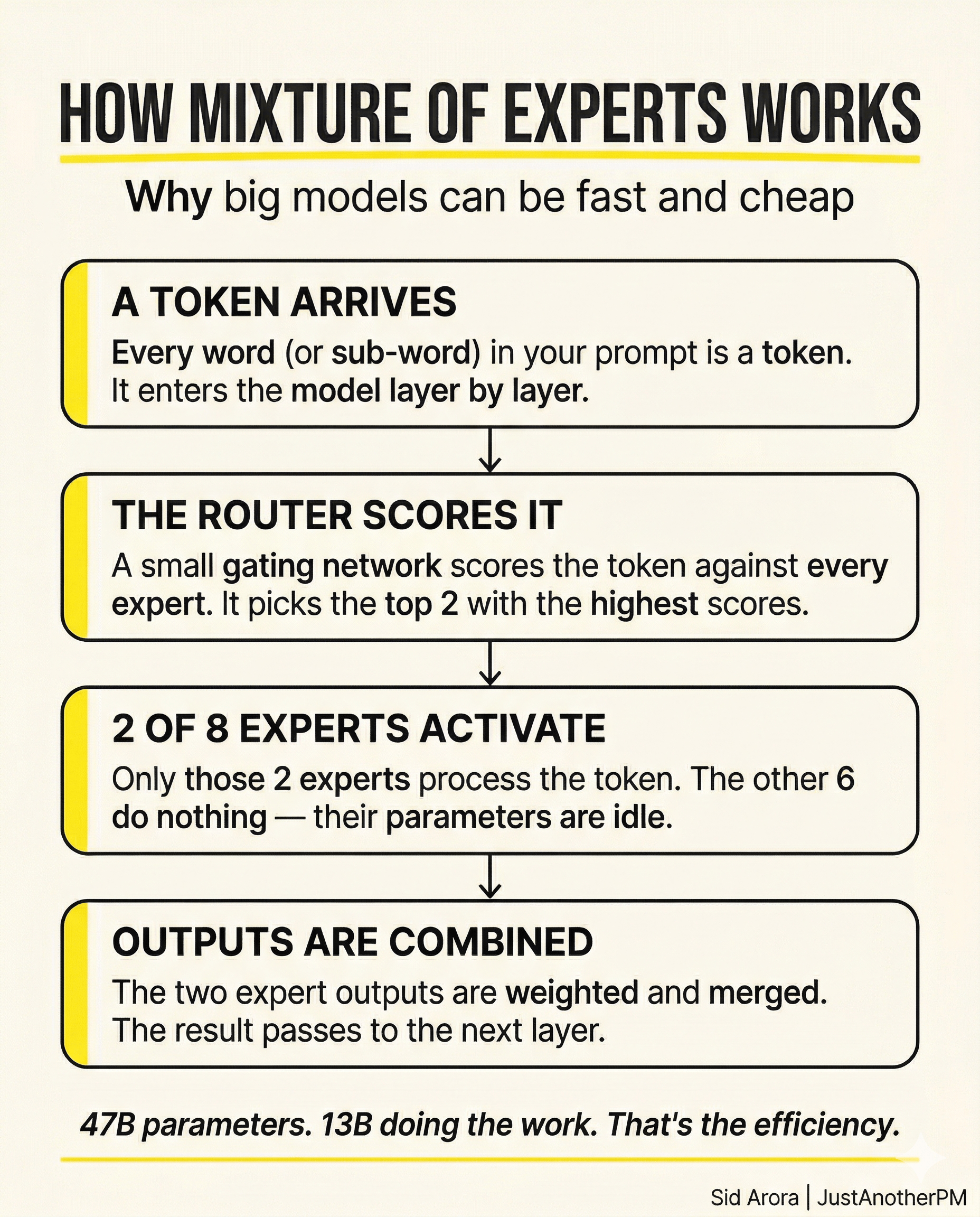
The router is a small, learned neural network layer that runs first, before any experts. It takes the incoming token (a piece of your prompt) and scores it for each expert.
Then it chooses the top two (in most cases) and routes that token there. Those two experts process the token individually and return their outputs.
The router combines that into a weighted sum, and the result flows to the next layer of the model. This happens at every layer, for every token.
The routing decisions are not fixed. They are learned during training. Across billions of training examples, the model learns which experts perform well at which inputs.
Some experts specialise in code. Some in factual recall. Some in reasoning. The model develops internal specialisation that you can’t see, but that shows up in performance.
The key point is that the experts which don’t get selected do nothing for that token. Their parameters are idle. They are in the building, but not in the room.
The Numbers That Make This Interesting
Mistral’s Mixtral 8x7B is the clearest public example of how this plays out. The name tells you the shape: 8 experts, each with 7 billion parameters.
But it’s not 56 billion parameters total, because the attention layers and embedding layers are shared across all experts. The total is approximately 47 billion parameters.
At inference time, only about 13 billion of those parameters activate per token.
So you are running a ~47-billion-parameter model, with the knowledge and capability that implies, at the compute cost of roughly a 13-billion-parameter dense model.
That’s less than 30% of the total parameter count doing work on any given token.
The results bear this out.
Mixtral 8x7B outperforms or matches Llama 2 70B across most benchmarks, while activating only about 13 billion parameters per token versus Llama 2 70B’s 70 billion.
You are getting 70B-class performance at something closer to 13B-class cost per token. Google’s Switch Transformer research demonstrated the training efficiency side.
By routing tokens to a single expert each (the simplest possible MoE setup), they got up to 7x faster pretraining than a dense model of equivalent parameter count, at the same compute budget. That efficiency at training time compounds, too.
Labs can train much larger models, reaching into the hundreds of billions or trillions of parameters, without proportionally increasing their compute spend.
Why This Connects to GPT-4 and The Cost Story
OpenAI has never officially disclosed its architecture.
However, SemiAnalysis and others describe GPT-4 as an MoE model, widely believed to use eight expert blocks, with a total parameter count in the hundreds of billions.
If accurate, it follows the same logic. A GPT-4 class model with MoE only activates a fraction of its parameters per token. That means lower compute per inference call.
Lower compute per inference call means lower cost per API request.
When GPT-4’s pricing dropped after its initial launch, and again when GPT-4o came with better pricing, that wasn’t just OpenAI being generous.
It reflected real reductions in the compute cost of serving the model, and the MoE architecture is part of that story. The same pattern shows up across the industry.
For example, Gemini 1.5 Pro, announced by Google in February 2024, is widely understood by researchers to use a mixture-of-experts design.
Again, Google hasn’t published full architectural details.
But the model’s ability to handle context windows of up to one million tokens at competitive pricing is consistent with sparse activation.
And that makes long-context inference controllable at scale.
Also read: ChatGPT Made You Smarter. AI Agents Will Replace You
The Tradeoffs Most People Don’t Mention
MoE is not a free lunch. There are tradeoffs worth knowing.
Memory requirements don’t shrink with compute. Even when only 13 billion parameters are active per token in Mixtral 8x7B, all 47 billion parameters must be loaded into memory.
You need to hold all the experts in VRAM, even the ones sitting idle. That makes serving MoE models memory-intensive, particularly at smaller deployment scales.
This is why you can’t straightforwardly run Mixtral 8x7B on a single consumer GPU, even though its active compute is that of a 13B model.
The memory footprint is still 47B. Load balancing is a real engineering problem. The router must distribute tokens evenly across all experts.
If it doesn’t, if certain experts get overwhelmed while others sit idle, you lose the efficiency benefits and create throughput bottlenecks.
Training an MoE model needs adding an auxiliary loss function specifically designed to encourage balanced expert utilisation. It’s not automatic.
Fine-tuning is harder. Dense models are relatively stable to fine-tune.
MoE models are prone to overfitting on small datasets, partly because the routing patterns can shift when you update weights on limited data.
For teams building fine-tuned applications, this is a real consideration.
But why does this matter when you are buying tokens?
Most PMs do not choose model architectures. They are choosing between offerings on a pricing page, but the architecture underneath shapes what you see.
When comparing models, you will notice that models with similar benchmark performance can have quite different prices.
Some of that is competition between labs. Some of it is hardware efficiency.
And some of it is the architecture, specifically, whether the model can achieve its capability level through sparse activation or requires dense computation on every token.
The models that can do more with fewer active parameters per token are inexpensive to serve at scale. That cost eventually flows through to API pricing.
So when you are in the budget talks, and someone asks why costs came down, or why one model is cheaper than another despite similar performance, this is the answer.
The Deeper Implication
There’s something worth sitting with here. For years, the assumption in AI was a rough correlation. It was all about more parameters, cost, and capability.
You had to pay for intelligence. The computational costs of frontier models were a barrier to building on them. MoE breaks that assumed relationship.

A model can be large enough to hold so much knowledge across many domains, while only drawing on the relevant slice for any given input.
Parameter count and inference cost are no longer the same thing.
That’s a genuine architectural shift, and it’s still playing out.
Researchers are exploring finer-grained MoE designs, improved routing algorithms, and methods to reduce memory overhead.
The efficiency gap between MoE and dense models at inference is likely to keep widening. The practical upshot is that the economics of AI products are very much better than they were a decade ago.
They will only continue to improve, not just because GPUs get faster, but because the models themselves are being designed to do more with less.
Next time the API bill comes up, you will know what’s actually driving it.
More from
Product Management Concepts






