





Hello
Open Claude right now. Ask it something hard. A maths problem. A tricky business question. Anything that requires more than a quick lookup.
You will see something new.
Before the answer appears, there is a pause. A little spinner. A block of text labelled "thinking" that expands and collapses. The model is working through it.

This is not a loading animation. The model is actually doing something different under the hood. It is generating intermediate steps, checking its own logic, and building toward an answer piece by piece.
Every major AI lab now has a version of this. OpenAI calls theirs o3 and o4-mini. Anthropic calls it extended thinking. Google calls it thinking mode. DeepSeek released an open-source version called R1.
And if you are a PM building with AI, understanding how this works is no longer optional. It changes your cost model, your latency budget, and which problems your product can actually solve.
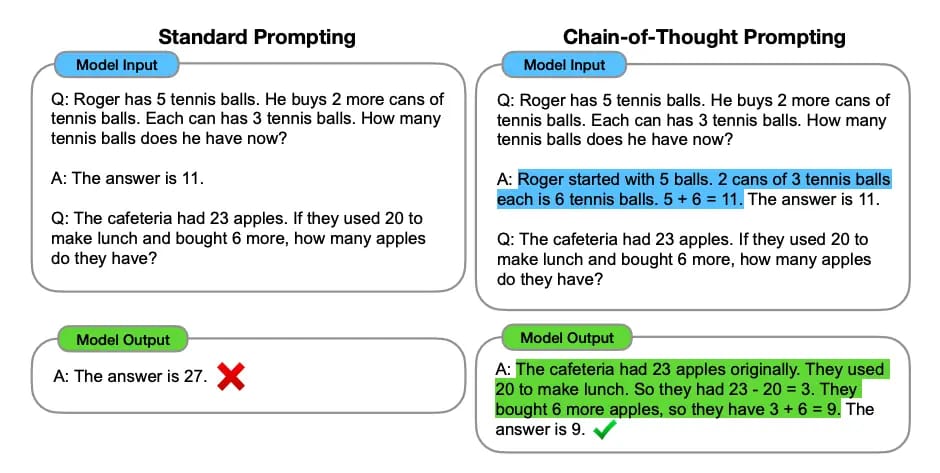
The Fast Answer vs The Thought Through Answer
Here is the simplest way to think about it. When you ask a regular LLM a question, it does one thing: it predicts the next word. Then the next word. Then the next. Really fast. It gives you the first plausible answer it lands on.
This is like asking someone a question and they blurt out the first thing that comes to mind. Often it is right. Sometimes it is confidently wrong.
A reasoning model does something different. Before it starts answering, it works through the problem step by step. It breaks it down. It considers options. It checks its own logic. Then it gives you the answer.
Same question. Same model. But one took the scenic route — and the scenic route is usually more accurate. Daniel Kahneman called this System 1 and System 2 thinking. System 1 is fast, instinctive, automatic. System 2 is slow, deliberate, effortful.
Regular LLMs are System 1. Reasoning models are System 2.
What Actually Happens When An LLM "Thinks"
The mechanism is called chain of thought. Instead of jumping straight from question to answer, the model generates a series of intermediate steps. Each step becomes context for the next one. The chain builds until the model reaches a conclusion.
Here is what it looks like in practice. A regular model sees: "If a train leaves London at 9AM going 120 km/h, and another leaves Manchester at 10AM going 150 km/h, when do they meet?" It tries to predict the answer directly. Sometimes it gets lucky. Often it doesn't.
A reasoning model does this internally:
"Okay, London to Manchester is about 320 km. Train A starts at 9AM at 120 km/h. By 10AM it has covered 120 km, so there are 200 km left between them. Now both are moving toward each other at a combined 270 km/h. 200 ÷ 270 = about 0.74 hours, which is about 44 minutes. So they meet around 10:44 AM."
Same model. Same knowledge. But by writing out the steps, each intermediate calculation becomes available for the next one.
The model can catch errors mid-chain and correct course.

This is not just prompting. You can ask any LLM to "think step by step" and it might try. But reasoning models are specifically trained to do this well, using reinforcement learning. They have been rewarded thousands of times for producing correct chains of logic, and penalised for sloppy shortcuts.
The training works something like this: give the model a maths puzzle with a known answer. Let it generate a chain of thought. If the final answer is correct, reward the whole chain. If it is wrong, penalise it. Over millions of examples, the model learns how to think through problems, not just how to predict answers.
The Thinking Budget
Here is where it gets practical.
Every reasoning model lets you control how much thinking it does. More thinking = better answers = more cost and latency.
Anthropic calls this the thinking budget — a token limit on how much internal reasoning Claude can do before it has to answer. Set it to 2,000 tokens and you get a quick but shallow think. Set it to 100,000 tokens and you get deep, methodical reasoning.
OpenAI's approach is similar. Their o3 model comes in three reasoning levels: low, medium, and high. Low is fast and cheap. High is slow and thorough.
Google's Gemini lets you set a thinkingBudget parameter that caps how many tokens the model spends reasoning. The model automatically scales effort to match task complexity — simple questions get a quick think, hard questions get a thorough one.
The model does not always use the full budget. Ask it something simple and it might think for 50 tokens even if you gave it 10,000. The budget is a ceiling, not a target.
This creates a new kind of product decision. Your engineering team used to choose which model to use. Now they also choose how hard that model should think. That is a cost-quality-latency dial that sits squarely in PM territory.
The Shift: Training Smarter vs Thinking Harder
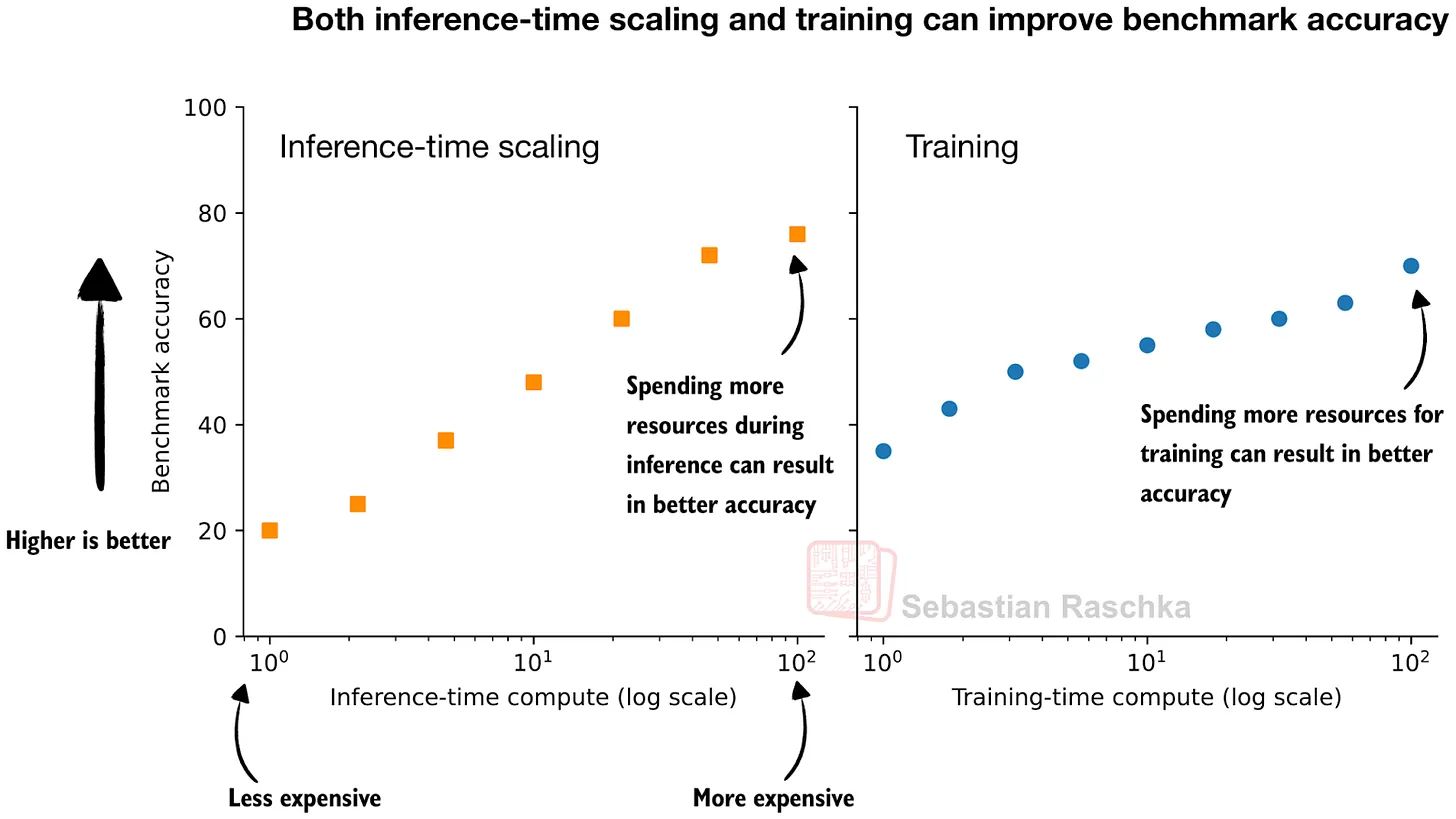
For years, the AI industry had one playbook for making models better: make them bigger. More parameters. More training data. More compute during training. This is called training-time scaling. Spend more money upfront to build a smarter model.
Reasoning models introduced a second lever: inference-time scaling. Instead of making the model bigger, let it think longer when it answers. And research has shown something remarkable: a smaller model that thinks harder can outperform a model 14 times its size that answers immediately.
Read that again. A small model with time to think beats a massive model that rushes. This is why every major lab pivoted. In 2024, the race was about who could train the biggest model. In 2026, the race is about who can build the best thinker.
Liking this post? Get the next one in your inbox!
The Ecosystem
Here is where things stand today.

OpenAI started the trend with o1 in late 2024, the first model explicitly trained to reason. It used hidden "thinking tokens" that users could not see. o3, released in 2025, opened this up further. On the AIME maths benchmark, o3 scores 96.7%. On graduate-level reasoning (GPQA), it hits 87.7%.
It is currently the strongest reasoning model on most benchmarks.
Anthropic built extended thinking into Claude Sonnet and Opus. The thinking is visible to the user — you can expand the block and read the reasoning chain. Claude's approach emphasises transparency: you can see how it reached the answer, not just what the answer is.
Google baked thinking into Gemini 3 Flash. Same model, two modes. Standard mode answers immediately. Thinking mode pauses, reasons, and responds. Gemini 3 Flash uses 30% fewer thinking tokens on average than Gemini 2.5 Pro for typical tasks.
DeepSeek did something nobody expected. They released R1, an open-source reasoning model that matches OpenAI o1's performance, at a fraction of the cost. R1 is 4x cheaper on input and 4x cheaper on output than o3. They also showed you could distil reasoning ability from a large model into a small one — their 32-billion-parameter distilled model outperforms OpenAI's o1-mini across multiple benchmarks.
The Controversy: Do They Actually Reason?
In June 2025, Apple published a paper called "The Illusion of Thinking".
Their researchers tested reasoning models on puzzles — Tower of Hanoi, river crossing problems, logic games — and found something uncomfortable.
They identified three performance zones:
Easy problems:
Regular models were actually faster and sometimes more accurate. The extra thinking was wasted.
Medium problems:
Reasoning models shone. The step-by-step approach genuinely helped.
Hard problems:
Both types collapsed completely. And reasoning models did something strange — they used fewer thinking tokens on the hardest problems, as if they were giving up.
The finding sparked a fierce debate. Critics argued the tests were flawed — some puzzles were literally unsolvable, and many failures came from models hitting output limits, not reasoning breakdowns.
But the core insight holds: reasoning models are not magic. They are a tool. They work brilliantly in the middle zone — problems that are too complex for a quick answer but not so complex that no amount of thinking helps. Maths, coding, multi-step analysis, structured problem-solving. That is their sweet spot.
When To Use Thinking (And When Not To)
This is the bit that matters for your product. Reasoning models cost more. They are slower. They use more tokens. Every token of "thinking" is a token you pay for.
A simple rule:
Use thinking when the answer requires multiple steps. Maths. Logic. Code debugging. Anything where getting it wrong is expensive and showing your work matters. Skip thinking when speed and cost matter more than precision. Chatbots. Summarisation. Creative writing. Quick lookups. The overhead is not worth it.
The best products in 2026 do not use one mode for everything. They route — sending simple queries to fast, cheap models and hard queries to reasoning models. That routing decision is a product decision, not an engineering one.
The model landscape just added a new dimension. It is no longer just "which model." It is "which model, and how hard should it think."
And the PMs who understand that tradeoff are the ones building products that are fast when they should be and accurate when it counts.
See you in the next one,
— Sid
More from
Other






