





Hey hey,
Here is a decision most AI teams get wrong. You are building a feature. Maybe it classifies support tickets. Maybe it extracts data from invoices. Maybe it summarises meeting notes. Your engineer opens the API docs and picks the most capable model available. Let's say Claude Opus or GPT-5... the flagship.
That's because it is the best. And you want the best for your users. Right? Six months later, your AI bill is five figures a month, response times are sluggish, and you realise 90% of your requests did not need that level of intelligence in the first place.
Right now, it is the most expensive mistake in AI product development. And it is everywhere. The question is not "which model is the smartest?" The question is "which model is smart enough for this specific job?" That distinction changes everything.
There Are Three Options, Not Two
People talk about "small models" and "large models" as if it were a binary choice. But it is not. Think of it as three options or tiers.
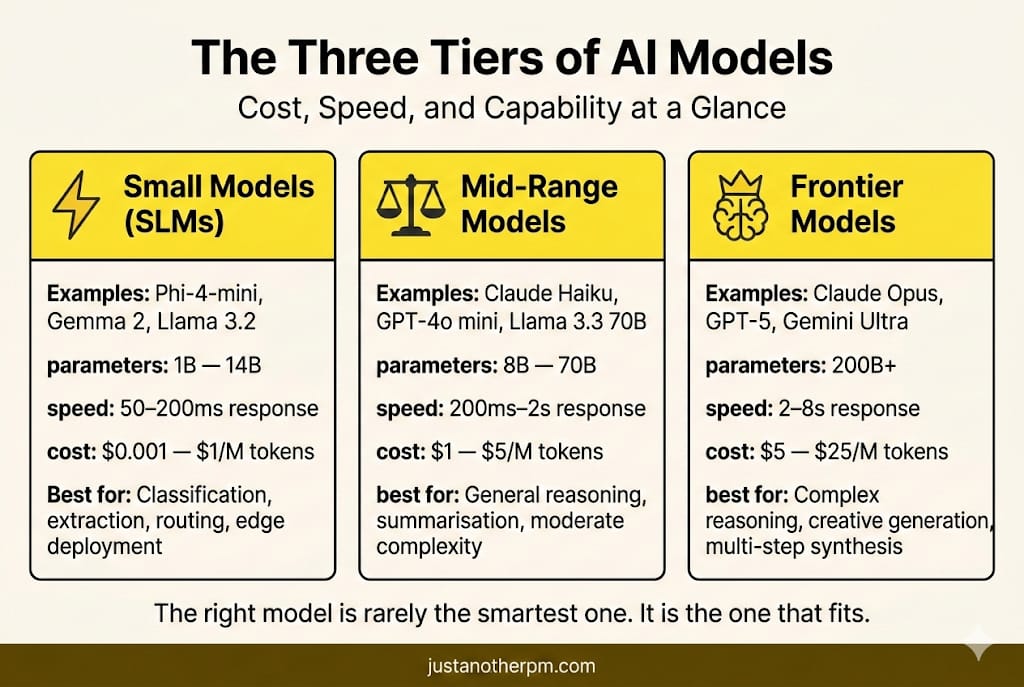
Tier 1: Small Language Models (SLMs).
These are models with roughly 1 to 14 billion parameters. Phi-4-mini (3.8B), Gemma 2 (2B/7B), Llama 3.2 (1B/3B), Phi-4 (14B) are some examples. They run on a laptop, while some run on a phone. These are fast, cheap, and capable at focused tasks.
Tier 2: Mid-range models.
Claude Haiku, GPT-4o mini, Llama 3.3 70B are some examples. These come with a strong general reasoning at a fraction of the flagship cost. These are the workhorses of production AI.
Tier 3: Frontier models.
Claude Opus, GPT-5, and Gemini Ultra are some examples. These have the broadest knowledge. They can manage heavy tasks and are best suited for reasoning.
But what surprises people is that Llama 3.3 70B, an open-source mid-range model, now outperforms the original GPT-4 on standard norms. A model you can run on your own servers beats the thing that blew everyone's minds two years ago. The ground is shifting fast.
Models that were "frontier" eighteen months ago are now mid-range performance at small-model prices.
The 92% Question
Here is the mental model that matters. When a 7-billion-parameter model sees a 92% accuracy on your specific task, and a frontier model achieves 95%, you need to ask a hard question: is that 3% gap worth 5x the cost and 5x the latency?
For some products, yes. For example, you want every percentage point when it comes to a medical diagnosis tool or a legal contract analyzer. For most products, it could be no. Let's say for tasks like classifying a ticket or summarizing an email, that 92% is more than good enough.
And the speed and cost savings compound fast. Now, that is not a hypothetical trade-off. It is the daily reality of production AI.
Where Small Models Win
Small models are not just "cheaper versions of big models." They have their own structural advantages that are important in production.
1. Speed.
A small model generates responses in 50 to 200 milliseconds. A frontier model can take 2 to 8 seconds for a similar query. If your product wants real-time responses, like live chat, autocomplete, or in-app suggestions, the latency gap can kill the product.
2. Cost.
Claude Haiku costs $1 per million input tokens. Claude Opus costs $5.
That is a 5x difference on input alone, and output tokens widen the gap further ($5 vs $25 per million).
At scale, the maths is brutal. A support chatbot handling 50,000 queries a day at 500 tokens each, switching from a frontier model to an appropriately sized model can cut costs by 80%. And then, when you run open-source small models on your own hardware, the gap widens to 50x or more.
3. Privacy.
Small models can run entirely on-premise. No data leaves your infrastructure. For healthcare, finance, and government, where data residency is non-negotiable, this is not a nice-to-have. It is a requirement.
4. Fine-tuning.
It is the real unlock. A small model fine-tuned on your proprietary data often beats a frontier model running on generic knowledge. Cursor, the AI code editor, built Composer-1, a custom model trained with reinforcement learning on real user coding sessions.
It generates at 250 tokens per second. That's about 4x faster than comparable frontier models. GPT-5 still beats it on raw benchmarks. However, for the specific coding tasks Cursor's users care about, Composer-1 is fast enough and smart enough to be the default.
Here's the key insight from Cursor's team:
"There is a minimal amount of intelligence necessary to be productive, and if you can pair that with speed, that is awesome."
That sentence should be on every AI PM's wall.
Where Frontier Models Still Matter
Small models are not the answer to everything.
There are tasks where you genuinely need the big guns.
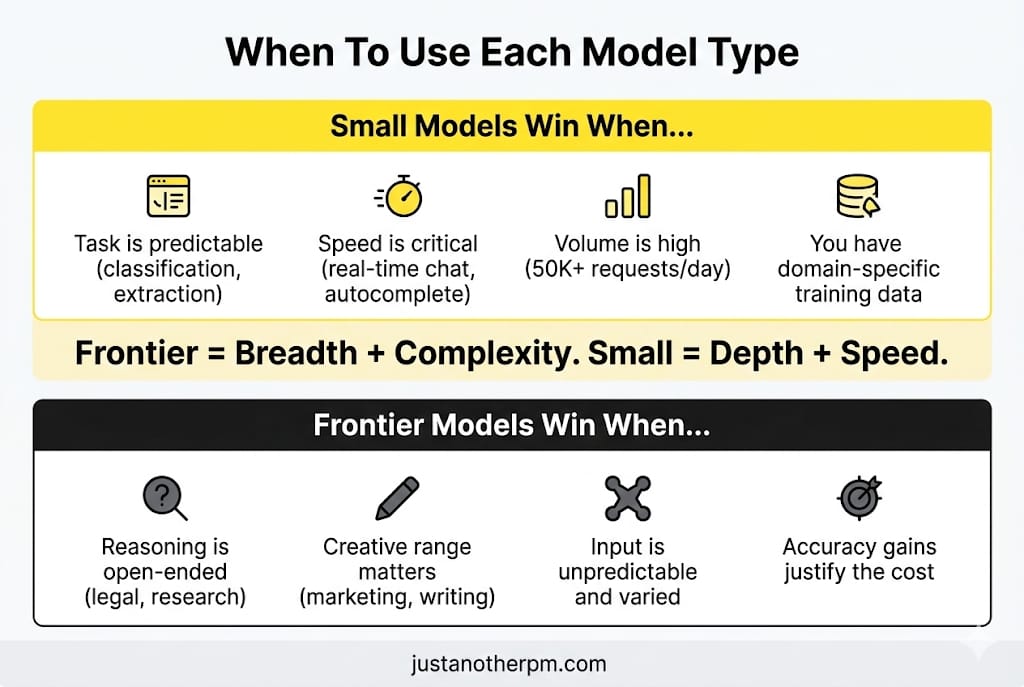
1. Open-ended reasoning.
"Analyse this 50-page contract and flag every clause that could expose us to liability." It requires broad legal knowledge, nuance, and the ability to hold a long document in memory. Small models choke on this.
2. Creative generation.
Writing a marketing campaign that feels human, varied, and strategically on-point. Frontier models have a wider "creative range" because they were trained on more diverse data.
3. Multi-step synthesis.
"Here are six research papers. Summarise the contradictions between them." It demands reasoning across multiple complicated sources simultaneously. It is where parameter count earns its keep.
4. Novel situations.
If your product faces high variability, such as questions that could be about anything with no predictable pattern, a frontier model's knowledge is an advantage.
A small model trained on customer support data will excel at customer support.
Ask it about tax law, and it will struggle to answer. Therefore, frontier models are for breadth and complexity. Small models are for depth and speed.
Liking this post? Get the next one in your inbox!
The Real Pattern: Model Routing
Instead of choosing one model, the smartest teams use several. It is called model routing. IDC predicts that by 2028, 70% of top AI-driven enterprises will use multi-model architectures.

The idea is simple. A lightweight classifier sits in front of your AI system. It monitors each incoming request and decides if it's simple, medium, or complex.
- A simple query ("What's my account balance?") goes to a small model. Fast. Cheap. Done.
- Medium query ("Summarise my last three transactions and flag anything unusual.") goes to a mid-range model. Balanced.
- Complex query ("I think I've been a victim of fraud. Walk me through my options and help me file a dispute.") goes to a frontier model. Worth the cost.
This single pattern, routing requests to the right-sized model, can reduce costs by 60 to 70% without impacting user experience. Even the model providers do this internally. When you use ChatGPT or Gemini, your request is not always going to the same model.
Behind that single interface, a mixture of specialised models handles different types of queries. You never notice the difference.
The Fine-Tuning Shift
There is a deeper trend underneath all of this. For the past two years, every AI product has run on the same handful of foundation models.
If you used Claude Sonnet, your competitor also relied on the same. It's the same intelligence, capabilities, and limitations. The only differentiation was your prompts and your data pipeline. But that is changing. Fine-tuning costs have dropped dramatically.
New platforms let you train a specialised model on your company's data without needing a team of ML researchers. And the results are striking.
- A small model fine-tuned on 20,000 domain-specific examples can match or beat a frontier model on that task.
- An automotive parts manufacturer deployed Phi-3 7B, fine-tuned on inspection reports, running on edge devices at the factory floor.
- An e-commerce company routes 95% of customer conversations to a fine-tuned Mistral 7B and only sends 5% to a frontier model.
The competitive advantage is shifting. It is no longer about who has access to the best model (because everyone does). It is about who has the best data to specialise a small model for their specific domain.
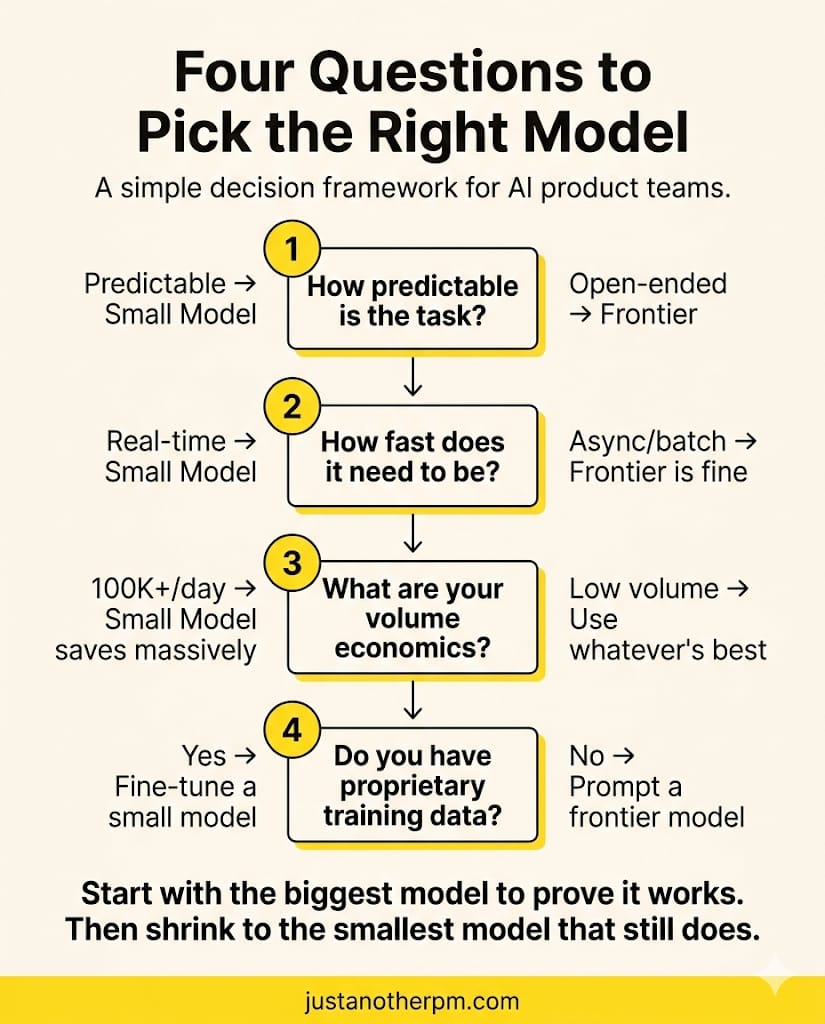
How To Think About The Decision
When deciding which model tier to use, run through these questions:
1. How predictable is the task?
If you can list the possible inputs and outputs, such as classification, extraction, and routing, a small model will likely be enough. If the input could be anything and the output requires real judgment, go bigger.
2. How fast does it need to be?
Anything user-facing and real-time (chat, autocomplete, live suggestions) benefits from smaller, faster models. Async batch processing (overnight report generation, weekly analysis) can tolerate frontier-model latency.
3. What are your volume economics?
100 requests a day? Model cost barely matters. 100,000 requests a day? The difference between $1 and $5 per million input tokens per query on self-hosted models versus dollars on frontier APIs is the difference between a viable product and a money pit.
4. Do you have proprietary training data?
If you have thousands of domain-specific examples, such as support tickets and legal documents, fine-tuning a small model on that data is almost always better than using a frontier model with generic insights.
The Bottom Line
The era of "just use the biggest model" is over.
The smartest AI products in 2026 are not the ones using the most powerful model. They are the ones using the right model for each task. Frontier models are becoming super capable every quarter. But small models are catching up faster than anyone expected.
The gap between a $1-per-million-token model and a $5-per-million-token model is shrinking. And for most production tasks, it was never as wide as we thought.
The PM who understands this builds products that are faster, cheaper, and just as good for the user. The PM who defaults to the biggest model available builds products that are slow, expensive, or impossible to scale.
The right model is rarely the smartest one. It is the one that fits. That's it for today.
See you in the next one,
— Sid
P.S. A PM replied to last week's email and said "I still don't know where to start with AI." I hear this every single week. So I made a free 6-day email course that fixes that. It is the best place to get started. Sign up here.
More from
Other






