





Hey,
Someone searching for "gf pizza" on Uber Eats wants gluten-free pizza.
Someone searching for "pan" might want bread (if they speak Spanish) or a cooking utensil (if they speak English). Someone typing "mozzarela" — one L — still wants mozzarella.
Old-school keyword search cannot handle any of this. It matches strings, not meaning.
If the exact word is not in the menu listing, the system returns nothing useful. For a platform serving 95 million monthly active users across 45 countries and multiple languages, that is a significant problem.
Search is the primary discovery funnel for Uber Eats — a large share of orders begin with someone typing into the search bar. When search misses intent, people bounce or fall back to browsing. When it works, they find what they want in seconds.
Uber's engineering team rebuilt their entire delivery search platform around semantic search — a system that matches meaning rather than keywords. This is what it means.
From Words to Meaning
Traditional search systems use lexical matching. They look for exact keyword overlap between what you type and what is stored in the index. This works well when the query is precise — "McDonald's" will find McDonald's.
But real queries are messy. Synonyms ("soda" versus "soft drink"), typos, shorthand, mixed languages, and ambiguous terms all break keyword matching.
Semantic search takes a fundamentally different approach. Instead of comparing strings, it converts both queries and documents into numerical representations called embeddings — essentially, coordinates in a high-dimensional space.
Items that are similar in meaning end up close together in that space, even if they share no words in common. "Gluten-free pizza" and "gf pizza" would land near each other. So would "pan" (the bread) and "baguette."
The challenge is not the concept. The challenge is making it work reliably across restaurants, grocery stores, and retail — in dozens of languages — at the scale Uber operates.

The Two-Tower Architecture
Uber adopted a two-tower model for their semantic search system. The name is literal: there are two separate neural networks (towers), one for queries and one for documents.
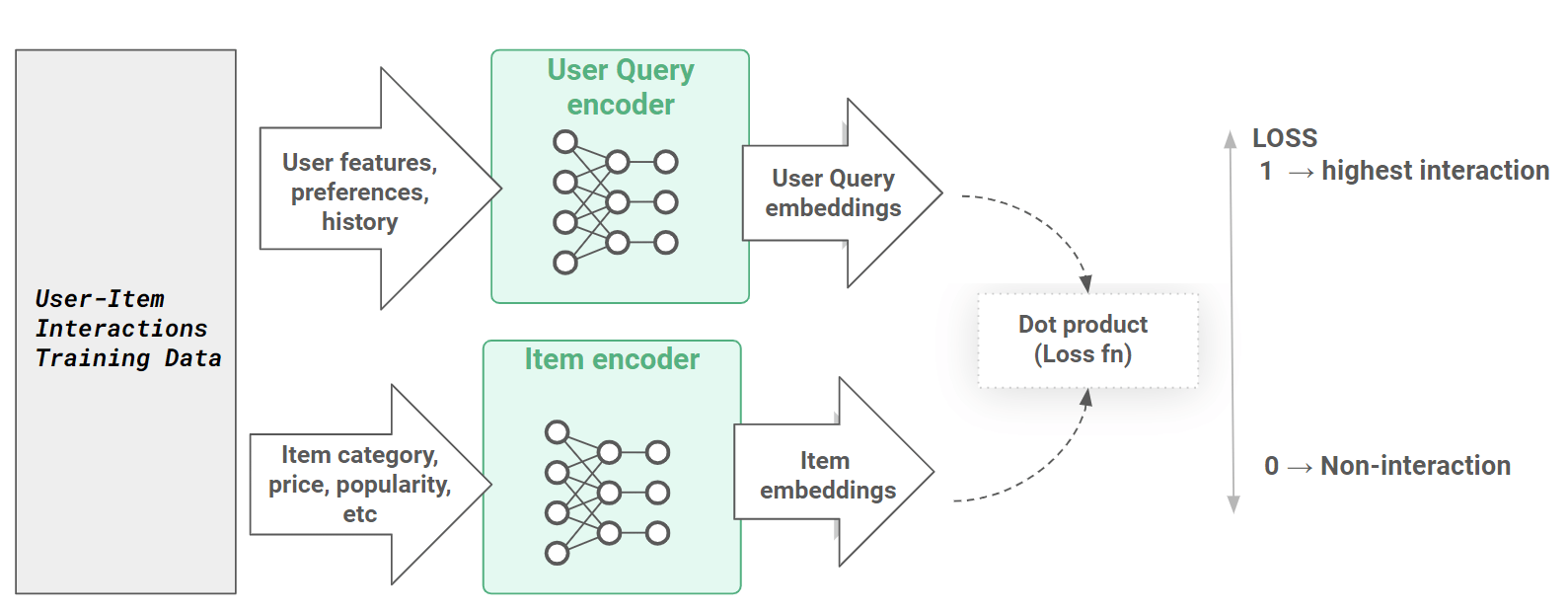
The query tower processes what the user types and produces an embedding — a numerical vector representing the meaning of the search. The document tower does the same for every item in the catalogue: every restaurant, every dish, every grocery product. Both towers map their inputs into the same shared space, so you can directly compare a query embedding against a document embedding to measure how similar they are.
The key advantage of splitting this into two towers is that the work can be decoupled. Document embeddings do not change every time someone searches — they can be computed in advance, offline, in large batches.
Only the query embedding needs to be calculated in real time when a user types something.
This separation is what makes the system feasible at Uber's scale. You are not running a heavyweight model on every search request. You are comparing a freshly computed query vector against a pre-built index of document vectors.
For the backbone of both towers, Uber used Qwen, a large language model from Alibaba, then fine-tuned it on Uber Eats' own data. This gives the model general world knowledge and cross-lingual ability from the base LLM, plus domain-specific understanding of food, restaurants, and grocery items from the fine-tuning.
A single embedding model now supports all Uber Eats verticals — restaurants, grocery, and retail — across all markets.
Finding The Closest Match in Billions of Documents
Once you have embeddings, you need a way to find the closest matches — fast. Comparing a query vector against every single document vector would be far too slow at Uber's scale, where the catalogue runs into the billions.
This is where approximate nearest neighbour (ANN) search comes in.
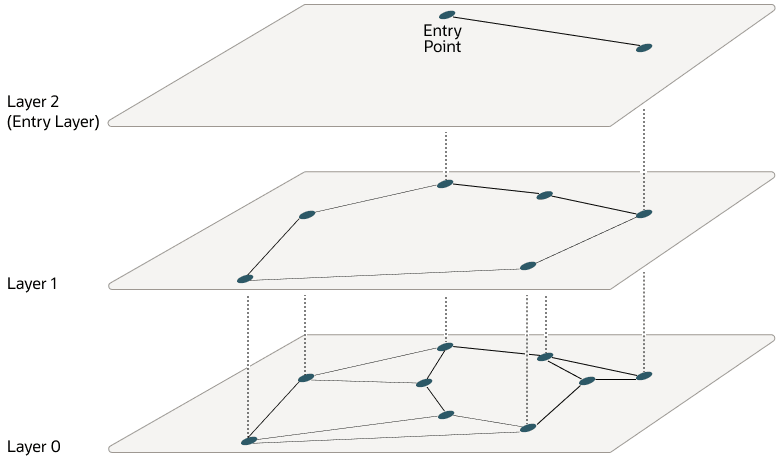
Instead of checking every document, ANN algorithms use clever data structures to find very close matches without exhaustively scanning the entire index. Uber uses a structure called HNSW — Hierarchical Navigable Small Worlds.
Think of it as a multi-layered map: the top layer has a sparse view of the landscape for quick, coarse navigation, and each layer below gets progressively more detailed. The search starts at the top, narrows down through the layers, and arrives at the nearest neighbours in milliseconds.
Before the ANN search even begins, the system applies pre-filters to shrink the candidate set.
These include geographic filters (which delivery hexagon the user is in), city ID, document type (restaurant versus grocery), and fulfilment type. These boolean filters run first and dramatically reduce the number of vectors the ANN search needs to examine — critical for keeping latency low against a multi-billion document corpus.
After ANN retrieves the top candidates, an optional micro-re-ranking step uses a lightweight neural network to refine the ordering before passing results to downstream rankers.
Making It Affordable: Matryoshka Embeddings
Semantic search is powerful but expensive. Storing and serving billions of high-dimensional vectors costs real money in infrastructure, and every millisecond of query latency matters for user experience. Uber tackled this with three levers.
Lever One: Tuning the K Parameter
Lowering the number of nearest neighbours retrieved per shard (the K parameter) from 1,200 to around 200 produced a 34% latency reduction and 17% CPU savings — with negligible impact on recall.
Lever Two: Quantisation
Instead of storing full-precision 32-bit floating-point vectors, they used 7-bit scalar quantisation. This cut compute costs further, reducing latency by more than half compared to float32 while keeping recall above 0.95.
Lever Three: Matryoshka Representation Learning (MRL)
The third — and most elegant — was Matryoshka Representation Learning, or MRL. Named after Russian nesting dolls, MRL trains a single model whose embeddings can be sliced at different lengths.
The first dimensions capture coarse, high-level information. Later dimensions add finer detail. This means the same model can produce a 128-dimension embedding for fast, rough matching or a 1,536-dimension embedding for maximum precision — without retraining separate models.
Uber trained with dimensions at [128, 256, 512, 768, 1,024, 1,280, 1,536], weighted equally.
In practice, they found they could serve 256-dimension embeddings with less than 0.3% recall loss for English and Spanish compared to full-size vectors — while cutting storage costs by nearly 50%.

Together, these optimisations let Uber run semantic search at global scale without the infrastructure bill spiralling out of control.

Liking this post? Get the next one in your inbox!
Keeping It Fresh Without Breaking Production
Uber's catalogue changes continuously. New restaurants open. Menus update. Items go in and out of stock. A search index that is not regularly refreshed will drift from reality.
1. The Catalogue Never Stops Changing
If embeddings do not reflect the catalogue changes, semantic similarity becomes outdated. So Uber runs a fully automated biweekly pipeline that retrains the embedding model, regenerates document embeddings, rebuilds the search index, and deploys the new index.
All without disrupting live traffic. The retraining and index rebuild happen in lockstep. There are no partial updates or mixed states.
2. Blue/Green... But at the Column Level
Usually, teams would deploy blue/green at the infrastructure level.
Uber considered this, but there was just one problem. It would roughly double storage, maintenance costs, and operational complexity.
Instead, they chose a single index with dual embedding columns:
- embedding_blue
- embedding_green
At any given time, one column addresses the production traffic, while the other remains inactive. During a refresh:
- The inactive column gets repopulated with fresh embeddings
- The active column remains untouched
Once validation passes, traffic flips to the newly populated column.
3. Three Build-Time Safeguards
Cost efficiency increases risk. Uber balanced it with strict validation gates. Every deployment must pass three automated checks.
1. Completeness Check
The system verifies that document counts in the new index match the source tables. This catches drift, partial ingestion, and pipeline failures. If the counts mismatch, the build stops.
2. Backward-Compatibility Check
The unchanged active column must be byte-for-byte equivalent between old and new builds. Any mismatch kills the run. It ensures the refresh process does not accidentally corrupt the serving column.
3. Correctness Check
The new index deploys to staging. The team replays real queries. They compare recall against the current production index. The new index must be at least as good as what is already live. At least as good on real traffic patterns. If it fails, it does not ship. Even after passing build-time checks, Uber adds runtime protection.
Each index column stores the model ID in its metadata. On sampled production requests, the system verifies if the model that generated the query embedding matches the model ID stored in the active index column.
If there is a mismatch due to configuration errors or version mix-ups, the system emits an error metric. If errors persist over a short window, the system automatically rolls back the model deployment.
The index remains unchanged. This prevents silent model-index incompatibility.
Where This Sits Today
Uber's delivery search platform now powers discovery across restaurants, grocery, and retail in 45 countries. A single semantic model handles all verticals and languages, refreshed every two weeks with automated safeguards at every stage.

The system is designed around a fundamental insight: at Uber's scale, the cost of search is not the model — it is the infrastructure to serve it. Every architectural decision reflects this.
Two towers decouple offline and online computation. Matryoshka embeddings let them trade precision for cost at inference time. Pre-filters shrink the search space before ANN kicks in. Quantisation compresses the vectors. And the blue/green column pattern lets them refresh the index without doubling infrastructure.
For anyone building search or retrieval systems: the interesting part of this architecture is not any single technique. It is how the pieces compose. Two-tower models, MRL, HNSW, quantisation, pre-filtering, blue/green deployment — none of these are new individually.
What Uber built is a system where each layer compensates for the tradeoffs of the others, and the whole thing refreshes itself every two weeks without human intervention.
That is the kind of engineering that is invisible when it works. You type "gf pizza," and gluten-free options appear in under a second. You do not think about the billions of vectors, the multi-layered graph traversal, or the automated deployment pipeline that just ran. You just order dinner.
At Uber’s scale, the cost of search is the infrastructure required to serve it. Every architectural decision Uber made reflects this constraint.
That's it for today. See you in the next one,
— Sid
More from
Other






