





In the last part, we learned how machines learned to see, read, and write and how LLMs generate text. But there’s one thing they still aren’t very good at: knowing when they are wrong.
If you have used ChatGPT or Claude, you have likely seen it: A beautifully written answer that sounds right but isn’t. You nod for a moment, then check the facts, and realize the model just… made it up.
That’s called hallucination.
And it’s one of the biggest open problems in AI.
LLMs are masters of language, not truth. They predict words, not verify facts.
They don’t check sources or confirm information. They just generate what sounds plausible based on what they have seen before. To fix this, AI needed a way to remember the world as it is, not just as it was during training.
When a model (aka LLM) is trained, it learns from a huge dataset collected at a specific point in time.
That “training snapshot” never updates on its own. So even if the world changes, new laws, new restaurants, new product updates, the model still relies on what it learned months or years ago.
That gap between what the model saw during training and what’s true today is why it often gets facts wrong or confidently invents details. That’s where Retrieval-Augmented Generation, or RAG, enters the picture.
What is RAG
RAG is like an LLM’s research assistant. It adds a simple but powerful step before the model starts writing: find relevant evidence. Here’s how RAG works:
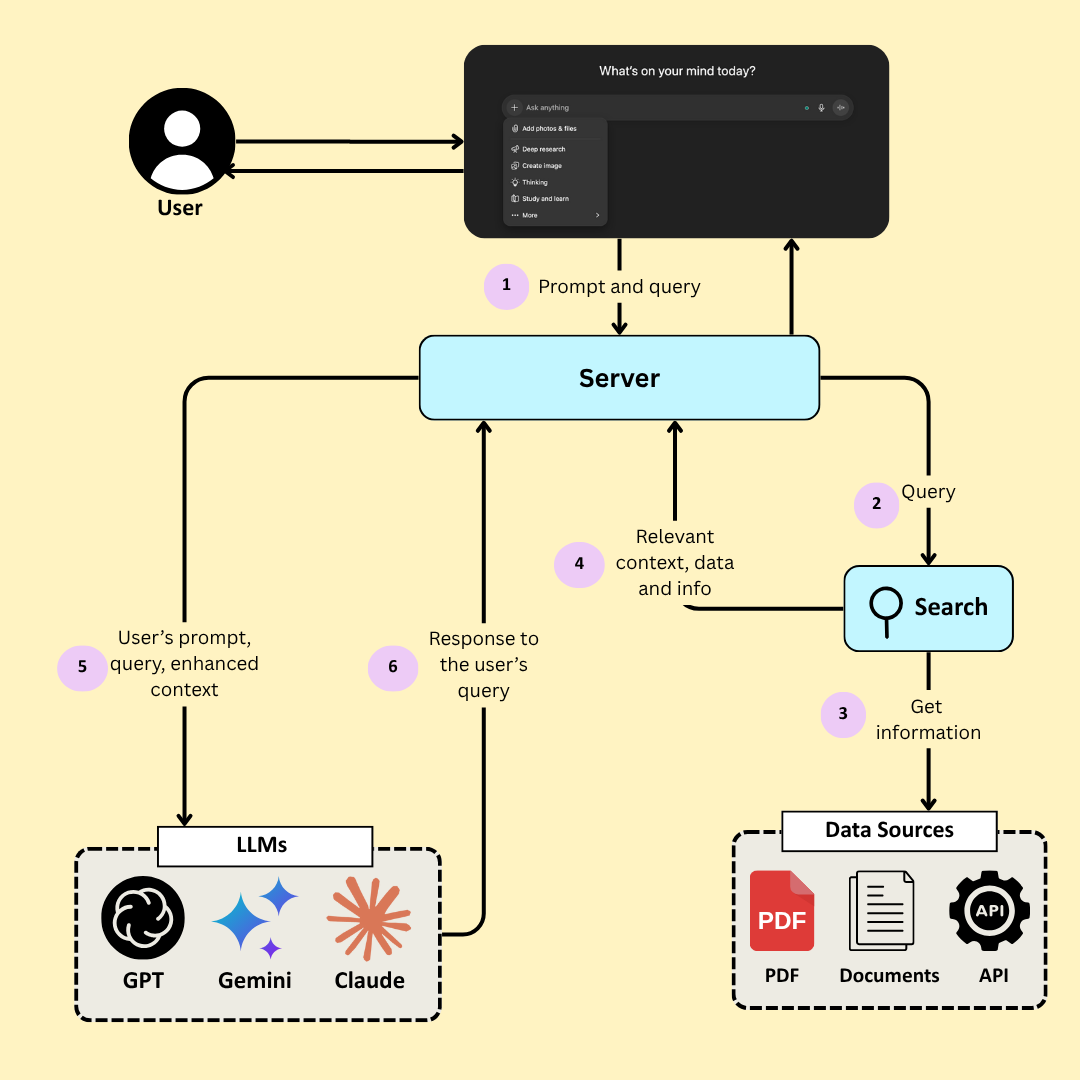
- You ask a question.
- The system searches through trusted data sources. These sources could be your company’s knowledge base, a live database, or the internet.
- It retrieves the most relevant information, data, and context. And sends it to a an LLM.
- Then the LLM consumes that information and uses it to generate a response for the user.
Instead of answering only from memory, the model gives evidence-based answers.
Imagine you ask a travel chatbot, “What are the best vegetarian restaurants open right now in Rome?” A regular LLM might guess based on what it learned months ago, maybe even make up a few names.
But a RAG-enabled system searches through a real data source, like your company’s knowledge base or a live API, and retrieves the latest restaurant information.
It then filters what’s currently open and uses that verified data to write a natural and accurate response.
RAG combines retrieval (to find truth) with generation (to explain it clearly).
As a product manager, RAG changes the way you design AI products. It’s no longer about just tuning prompts or writing clever instructions. It’s about connecting your model to the right data, safely and intelligently.
Here are the questions a PM starts asking once RAG enters the picture:
- Where does our model get its information from?
- How current is that data?
- Are those sources verified and transparent?
- Can we explain how an answer was generated if a user challenges it?
RAG is the foundation of trustworthy AI. Especially in products where factual accuracy matters, such as the finance dashboards, healthcare reports, and customer support bots, RAG is the difference between “wow” and “uh-oh.”
But RAG isn’t always perfect.
If the retrieval step pulls outdated or irrelevant data, the model will still produce a confident, but wrong answer. As a PM, you are not just designing the AI’s tone or flow but designing its relationship with data, deciding what truth looks like in your product.
Liking this post? Get the next one in your inbox!
Embeddings: The Hidden Hero of RAG
To understand RAG deeply, you first need to understand embeddings.
They are what make every modern AI system feel intelligent.
Let’s start with a simple question: When you search for “cheap vacation,” and the system also shows results for “budget travel,” how did it know they mean the same thing? There’s no exact word match, yet it got it right.
That’s the work of embeddings. Embeddings are how AI understands meaning. They convert messy and emotional human language into numbers that machines can work with.
Every word, sentence, or document is converted into a long list of numbers known as a vector. Each number captures a small aspect of meaning, like tone, topic, or context.
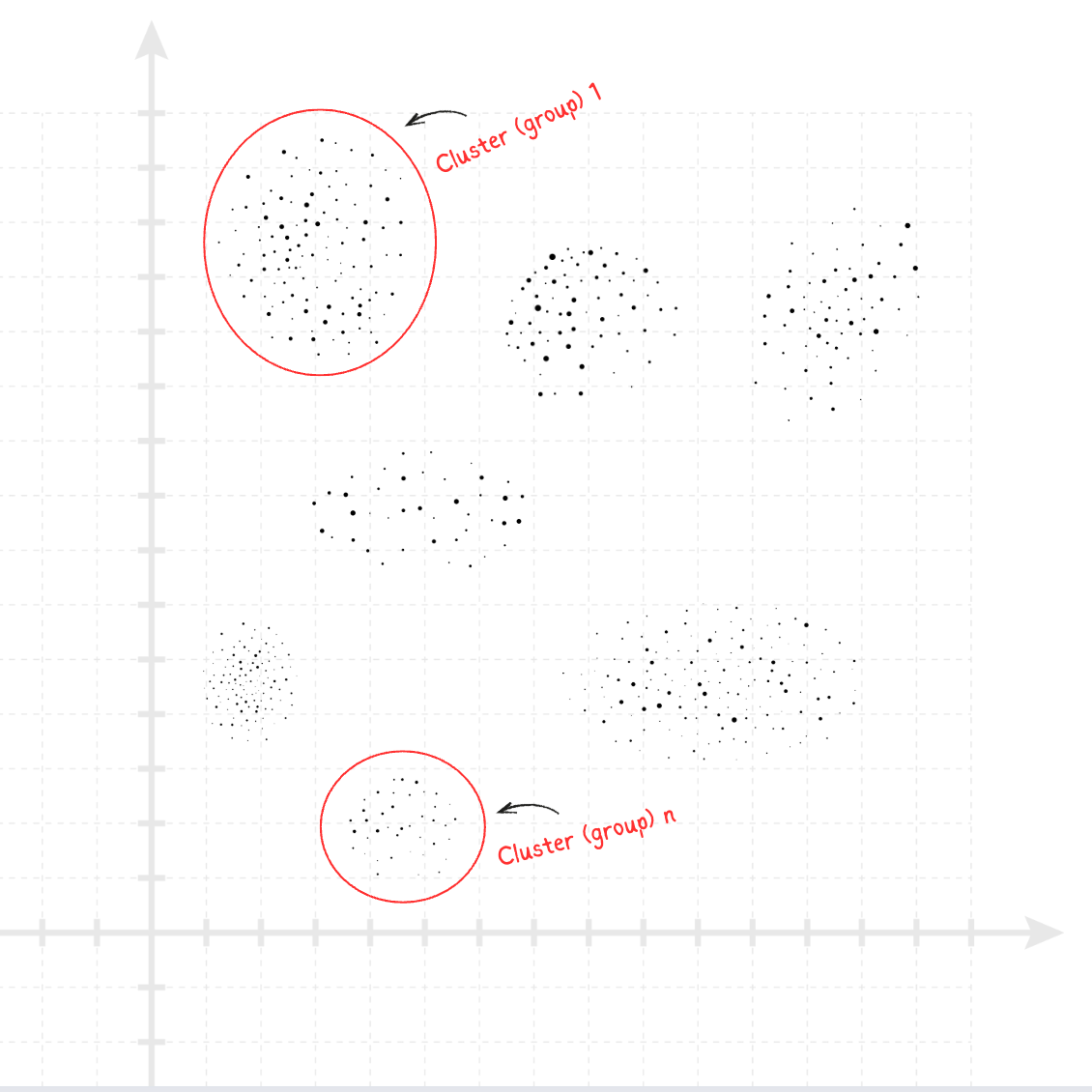
When plotted in a huge mathematical space (imagine a 3D map with billions of coordinates), words with similar meanings end up near each other. It’s like a map of ideas:
- “Vacation,” “travel,” and “holiday” cluster (group) in one area.
- “Invoice,” “payment,” and “tax” sit in another.
- “Dog,” “cat,” and “puppy” form their own neighborhood.
The closer the two points are, the closer their meanings.
So when you type “cheap vacation,” the system doesn’t just look for that phrase. Instead, it looks for everything near it in this meaning-space. That’s why it can show results for “affordable trip” or “low-cost getaway.”
Without embeddings, AI systems would only recognize exact words. With them, they recognize intent. And that’s the difference between a dumb keyword search and a smart, conversational AI.
Embeddings power almost everything that feels “natural” in modern AI:
- Semantic search: Finding results that match meaning, not wording.
- Personalized recommendations: Grouping similar users or products by context.
- Chat context: Helping the model understand what you are asking.
- RAG pipelines: Retrieving the most relevant knowledge before the model answers.
Without embeddings, even RAG wouldn’t work because the system wouldn’t know which data to retrieve.
Imagine you are building a customer support chatbot. A user types: “How can I change my billing info?”
In your company’s documentation, the relevant article is titled “Updating your payment details.” There’s no word overlap between “change” and “update” or “billing info” and “payment details.”
But through embeddings, both the query and the article are mapped into the same meaning region. The system recognizes they belong together and retrieves the correct doc instantly.
That’s what is at play every time an AI system seems to “get” you.
If RAG is about trust, embeddings are about understanding. They help your AI move beyond literal commands into true comprehension of user intent.
As an AI PM, this changes how you think about product decisions. You will start paying attention to:
- Data coverage: Do your embeddings represent every topic users care about?
- Freshness: Are you updating embeddings as your content changes?
- Diversity: Are you covering multiple ways users might express the same intent?
These are product decisions that define user experience.
An AI that “understands” users feels magical. An AI that misunderstands them feels broken.
Embeddings are the line between the two.
In a Nutshell
RAG and embeddings work hand in hand. Embeddings help the system find meaning. RAG helps it find the truth. Together, they make modern AI reliable, explainable, and grounded.
Before RAG, models could talk. Now, they can research.
Before embeddings, they could read words. Now, they can grasp ideas.
That shift, from words to meaning, from memory to retrieval, is what makes today’s AI feel closer to reasoning than recitation.
And for product managers, understanding these two concepts is the difference between building an AI that sounds intelligent and one that acts intelligently.
RAG and embeddings help AI find the right information. But how does it remember what you said five messages ago? How does it keep track of context, without losing focus or repeating itself?
That’s where context windows and memory come in, the next building blocks of true intelligence in machines.
That is it for today
See you soon
—Sid
More from
Fundamentals of Product Management






